En este pequeño articulo explicaré como consumir una vista de Gobierno abierto
Instalación de librerías necesarias
Para hacer un análisis de datos en Python una de las mejores librerías es Pandas y para consumir servicios de Junar hay que instalar junar-api-python
Para instalar pandas se puede realizar desde Pip (recomendable en un entorno virtual con virtualenv)
$ pip install pandasy para instalar el cliente de junar se puede hacer
$ pip install git+https://github.com/Junar/junar-api-python-client.gitAdicionalmente se pueden agregar más librerías de utilidades como matlibplot, pero para simplificar este texto no las vamos a instalar.
Creando un pequeño script
Para obtener los datos ejecutamos lo siguiente, para obtener "Mi token" debemos ir a la sección de desarrolladores de datos abiertos.
from junar import ApiClient
junar_api_client = ApiClient('Mi token')
datastream = junar_api_client.datastream('COMPR-PUBLI-DEL-MINIS')
datos = datastream.invoke(output = 'json_array')
datos = datos['result']COMPR-PUBLI-DEL-MINIS es un identificador de la vista que se obtiene navegando por cada vista en Junar en la pestaña de información. El API la solicitamos en json y por defecto es retornada en un diccionario que tiene los datos en la clave result
Los datos retornados están un poco sucios osea no está formateados de manera que puedan ser procesados directamente, por lo que hay que hacer código auxiliar para garantizar que se pueden hacer operaciones matemáticas sobre los datos.
import re
def get_datos_limpios(lista_m):
for lista in lista_m:
monto = re.findall(r"[\d,\.]+", lista[2] )
if monto:
try:
monto = float(monto[0].replace(",", ""))
except:
monto = 0.0
else:
monto=0.0
yield [ lista[0], lista[1], monto, lista[3] ]Por último vamos a procesarlo con Pandas, en este caso vamos a obtener cuales son los 10 montos más altos en orden
import pandas as pd
df = pd.DataFrame(list(get_datos_limpios(datos[1:])), columns=datos[0])
result = df.sort_values(by='Monto', ascending=False)Por último vamos a exportarlo a csv para poder abrirlo con LibreOffice calc
result.to_csv("result.csv", encoding="utf-8")por defecto exporta en ascii, y da problemas con las tíldes, por eso el encoding debe ser utf-8
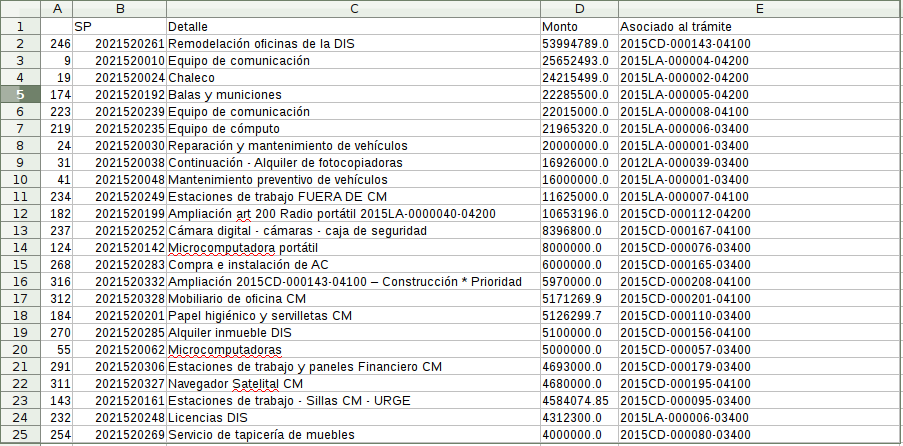
Resultado